Data Governance: Vom Data Profiling zur ganzheitlichen Leistungsbewertung von Daten
Wie Data Governance zum Innovator wird und Mehrwert liefert
Viele Unternehmen wandelten sich in den letzten Jahren zu agilen Organisationsformen, um sich den Herausforderungen von schnellen Anforderungsänderungen besser stellen zu können. Auch das Unternehmen, für welches ich tätig bin, befindet sich mitten in diesem Wandel. Hinzu kommt, dass Daten und datengetriebene Prozesse immer stärker im Fokus stehen. Wer einen Vorsprung in der Datenintelligenz erlangt und diesen optimal zu nutzen weiß, erlangt auch einen erfolgskritischen Wettbewerbsvorsprung, den es stetig auszubauen bzw. auf lange Sicht zu halten gilt.
Dieser Herausforderung müssen sich insbesondere BI (Business Intelligence) Bereiche stellen, aber auch die Bereiche, die sich mit der Thematik "Data Governance und Data Quality" beschäftigen. Diese Bereiche wurden und werden häufig immer noch eher als Bremser, statt als Förderer einer agilen Datenintelligenz angesehen. So sind in den letzten Jahren immer mehr Parallel-Bereiche entstanden, die sich mit dem Thema Big Data und Digitale Transformation beschäftigen. Irrwitzigerweise sind damit weitere Silos in den Unternehmen entstanden, was eigentlich nicht der Sinn von agilen Organisationsformen ist. Damit sind die Erfolgschancen von Big Data Initiativen meiner Meinung nach von vornherein begrenzt. Anfänglich erscheint es sinnvoll neue Verfahren in isolierten bzw. geschützten Umgebungen erst einmal zu testen und zu optimieren. Wer dies aber zu lange betreibt verhindert eine nachhaltige Veränderung und nimmt sich selbst die erhofften Chancen, daraus einen Wettbewerbsvorsprung zu entwickeln. Erfreulicherweise erlangen immer mehr Organisationen diese Erkenntnis. Sie beginnen stärker ihre Prozesse „End to End (E2E)“ vom Kunden her zu denken und zu organisieren sowie das Datenmanagement daran auszurichten. Das Silo Denken und Handeln wird aufgelöst und fördert die selbstorganisierte Zusammenarbeit unterschiedlichster Disziplinen. Was vorher unmöglich war, wird möglich und schafft neue Kundenlösungen.
Natürlich wurde auch unser Bereich „Data Governance und Data Quality“ innerhalb des Business Intelligence Competence Center anfänglich als Bremser gesehen.
Daher ist es es für uns eine stetige Herausforderung zu beweisen, dass wir einerseits zur Erlangung einer qualitativen und nachhaltigen Datenintelligenz ein unerlässlicher und wichtiger Teil im Datenmanagement-Prozess sind. Anderseits müssen wir einen früh erkennbaren Mehrwert hinsichtlich Kostenoptimierung, Steigerung und Sicherung von Chancen, Qualität und schneller Lernkurve liefern können. Das Ganze dann auch noch in sehr kurzen Zyklen, z.B. innerhalb eines Sprints von 2 – 4 Wochen aber auch langfristig.
Diesen Beweis konnten wir (Data Governance) vor einigen Monaten im Rahmen eines Projekts erbringen. Wir entwickelten innerhalb von 4 Wochen im laufenden Projekt ein Verfahren, das es uns ermöglicht in kurzer Zeit die Leistungsfähigkeit von umfangreichen strukturierten Daten hinsichtlich Aussagekraft gewünschter Kennzahlen sowie die Wirksamkeit (Erfolgsgrad) datengetriebener Prozesse zu bewerten.
Das Verfahren bezeichnen wir als „Leistungsbewertung von Daten nach dem Rapid Prototyping Verfahren“.
Das Verfahren ist in 4 Schritte aufgeteilt:
- Anforderung definieren
- Datenmodell entwickeln
- Analysemodell entwickeln
- Reportmodell entwickeln
Als Vorlage haben wir uns an dem Big Data Lifecycle Modell orientiert.
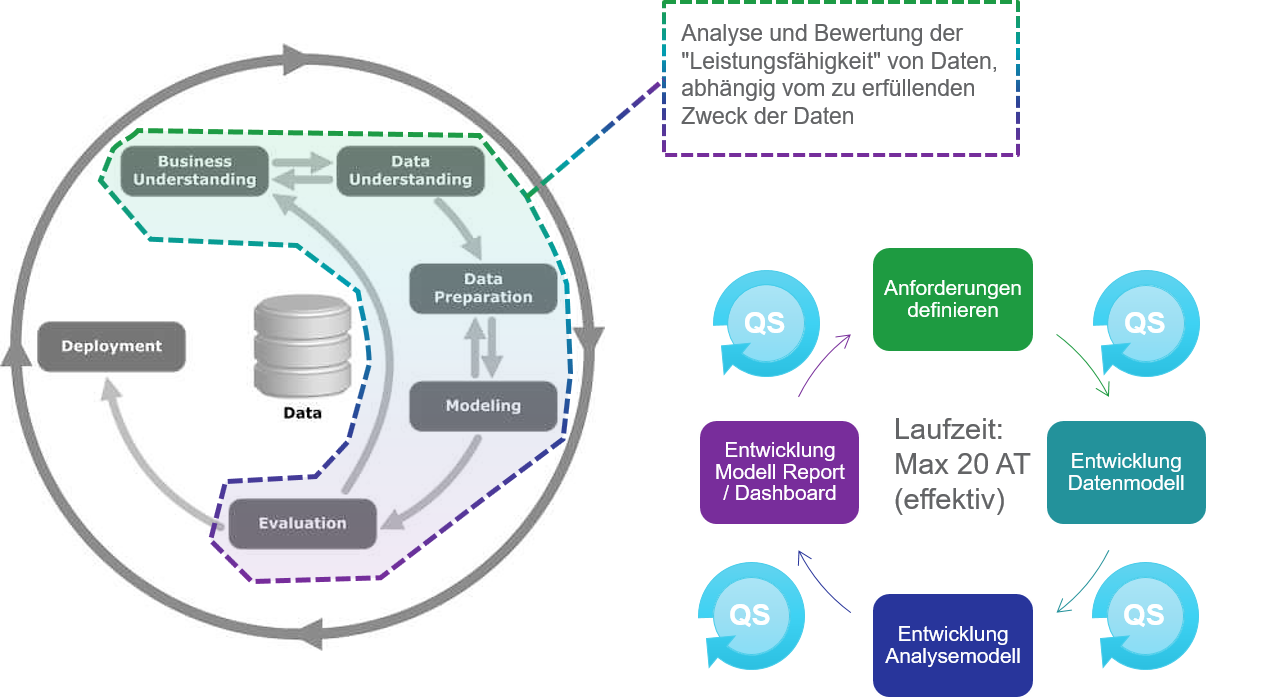
Das Verfahren wurde so robust gestaltet, das verschiedene Methoden immer wieder neu kombiniert werden können. Wie der Werkzeugkasten eines Handwerkers. Mit dem Hammer wird ein Nagel in die Wand geschlagen, mit der Zange wird der Nagel wieder herausgezogen. Der Handwerker entscheidet über die Größe und Art des Hammers, abhängig von der Beschaffenheit des Nagels und der Wand. Damit erlaubt das Verfahren verschiedene Kenntnisstände und vorhandene Werkzeuge zu nutzen wie aber auch diese stetig und flexibel anzupassen bzw. zu erweitern.
Unsere Erfahrung hat gezeigt, dass es hilfreich ist die Reihenfolge der Schritte einzuhalten. Da es aber ein Kreislauf ist, werden die Schritte immer so lange innerhalb eines Sprints durchlaufen, bis das Team entscheidet einen Ergebnisgrad von 60 – 80 % erreicht zu haben und somit eine gute Bewertung der Leistungsfähigkeit der Daten erlaubt. Zwischen den Schritten gibt es immer wieder Qualitäts-Schleifen. Vergleichbar mit den Daily-Meetings aus Scrum.
Ein weiteres für uns unverzichtbares Element zum flexiblen und schnellen Aufbau eines Prototypens ist die Softwarelösung InfoZoom für ad-hoc Data Profiling, Analyse und Reporting. (Anm.: Normalerweise nenne ich keine Softwarelösungen, habe aber für das Verfahren bis heute nichts Besseres gefunden. Die Vorgehensweise in Kombination mit der Softwarelösung InfoZoom und die einzigartige Methode der Datenvisualisierung, hat einen sehr hohen Anteil an dem Erfolg einer optimalen Leistungsbewertung von Daten gemeinsam im Austausch mit Personen, die nicht so affin im Datenmanagement sind.)
Da unser Verfahren sehr schnell weitere Begehrlichkeiten weckt und dazu verleitet etablierte sinnvolle Prozesse zu umgehen, haben wir eine klare Abgrenzung formuliert, wann das „Rapid Prototyping Verfahren“ zum Einsatz kommt und was es nicht leisten kann.
Definition (Rapid) Prototyping
Prototyping kann uns die richtige Richtung weisen,
- wenn Unklarheit herrscht,
- wenn widersprüchliche Meinungen bestehen,
- wenn der Wert einer Idee nicht klar ist.
(Rapid) Prototyping
- hat eine kurze Laufzeit (Rapid = 1 Sprint, max. 20 AT).
- ist ein kontrolliertes Experiment mit realen Daten.
- ist zum Scheitern verurteilt.
- ist keine betriebsfähige Lösung.
- der Prototyp selber ist ein Wegwerf-Produkt.
- generiert nutzbringendes Wissen (Lernkurve), welches sofort weitergegeben werden kann.
Zu guter Letzt ist es absolut wichtig ein interdisziplinäres Team zusammenzustellen, das zu 100% in dem definierten Zeitraum eines Sprints zur Verfügung steht. Dabei darf auf keinen Fall eine kompetente Person aus dem Fachbereich fehlen. Fehlt diese Person, kann das Vorhaben nicht durchgeführt werden!
Nachfolgend die 4 Schritte ausführlicher beschrieben.
Schritt 1 – Anforderung definieren
In diesem Schritt geht es darum schnell zu verstehen, was die Anforderung des Fachbereichs ist und diese simpel und verständlich zu dokumentieren. Erfahrungsgemäß kommt man innerhalb von 8 Stunden, verteilt auf 2 Tage, zu guten Ergebnissen, die es erlauben zum nächsten Schritt zu gehen.
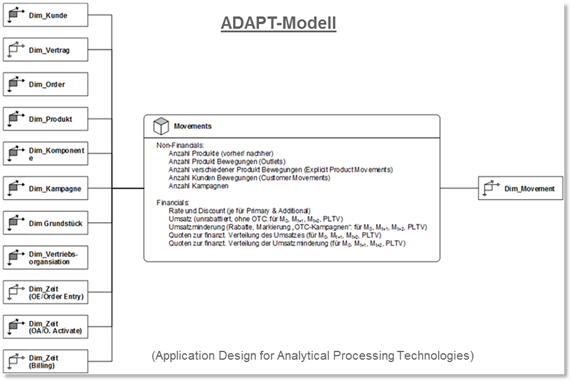
Hierbei wird der Fachbereich gebeten, seine Anforderung in ca. 3 – 5 Sätzen zusammenzufassen. Dann werden die Kern- und die wesentlichsten Subfragen, die es zu beantworten gilt, herauskristallisiert und dokumentiert. Die Fragen werden so strukturiert dokumentiert, dass sich hieraus bereits ein multidimensionales Datenmodell ablesen lässt, welches für den Fachbereich noch verständlich ist und sich in seiner Anforderung wiederfindet. Dann werden die Fragen in Kennzahlendefinitionen übersetzt. Als letztes wird noch dokumentiert, welche Attribute in einem Report erwartet werden und in welcher Reihenfolge. Die Dokumentation kann z.B. mit einem Mindmapping -Tool erfolgen. Reifere Organisationen gehen im Laufe der Zeit zur ADAPT-Modellierung über. Ein weiterer späterer Schritt zu einem höheren Reifegrad könnte der „Model Driven Design Ansatz (MDD)“ sein. (Hierzu demnächst mehr.)
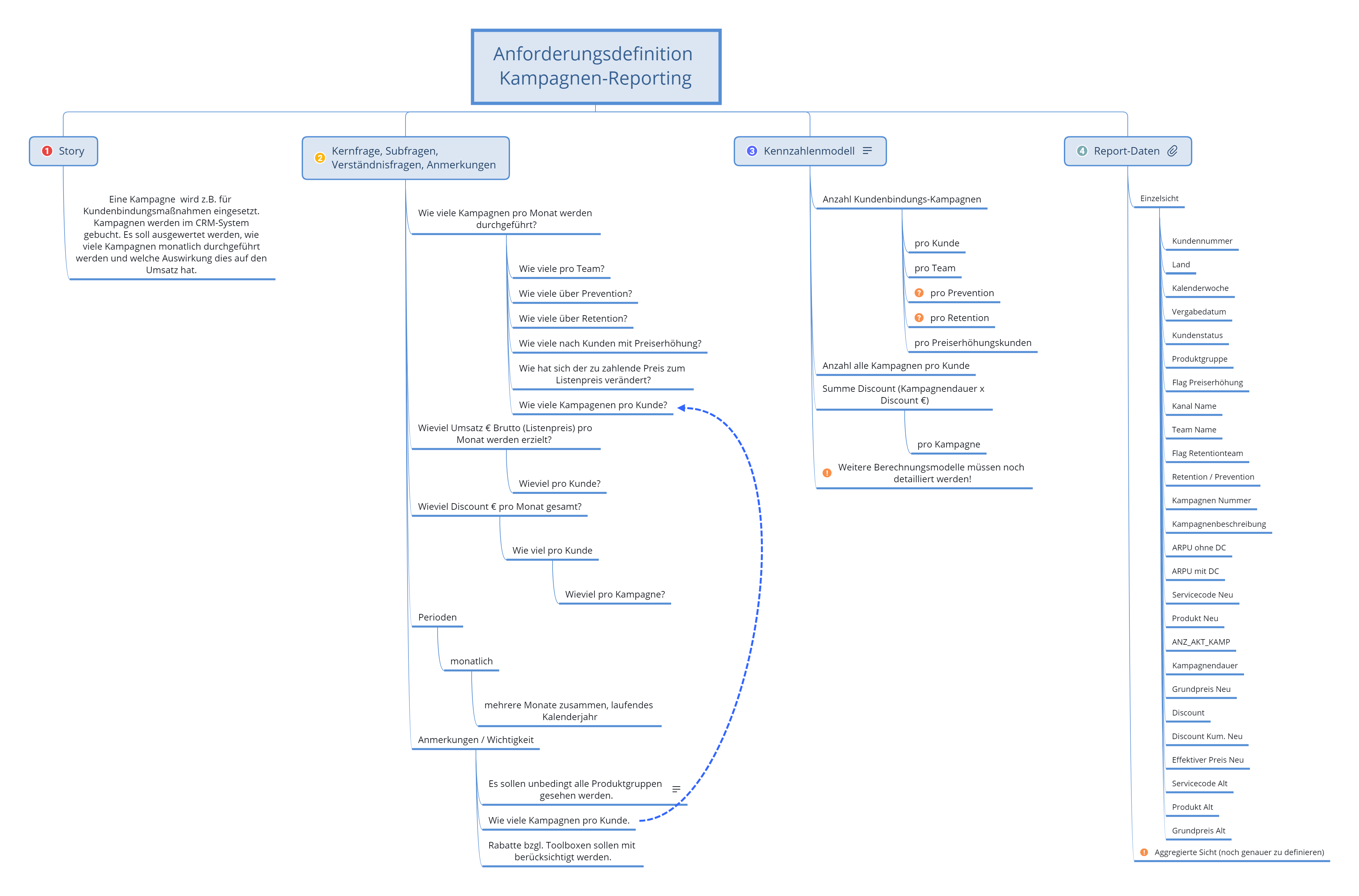
Schritt 2 - Datenmodell entwickeln
Im Schritt zwei wird dann geklärt aus welchen Quellen, welche Tabellen und Attribute benötigt werden. Ist der nötige Datenumfang weitestgehend geklärt und die Zugriffe legitimiert, beginnt nun die Analyse und Aufbereitung der Daten mit dem Ziel, diese in einen sinnvollen Zusammenhang zu bringen und entsprechend simpel und verständlich zu dokumentieren. Die Datenzusammenstellung kann z.B. in einer Datenbank, meist im Data Warehouse (DWH), erfolgen. Häufig geht es auch um Daten, die noch nicht so weit im DWH vorliegen. In den Fällen kommt bei uns bereits InfoZoom zum Einsatz.
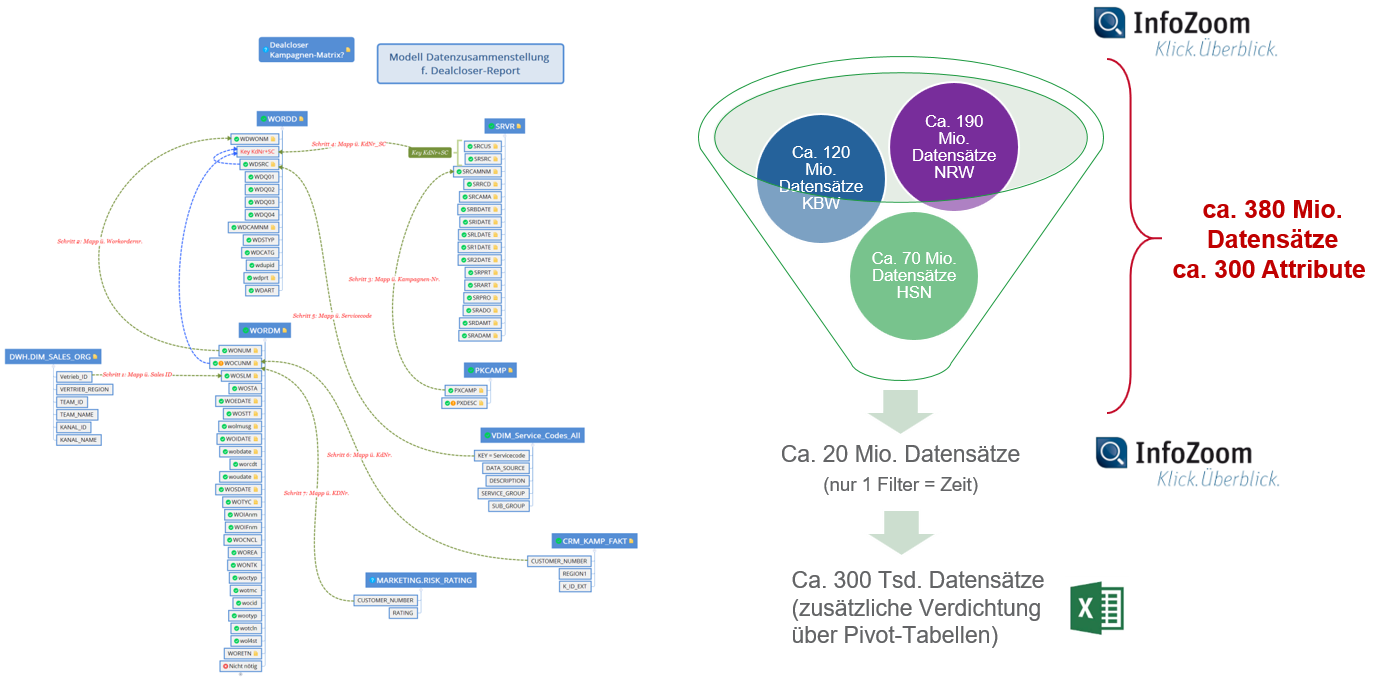
Schritt 3 – Anlalysemodell entwickeln
Nun liegen die Daten in einem Umfang vor, dass auf diesen Datenbestand die Analysemodelle entwickelt werden können. Bei uns wird dies zu 90% mit InfoZoom durchgeführt. In iterativen Schritten, innerhalb weniger Tage, werden die erarbeiteten Ergebnissen den Teammitgliedern präsentiert und gemeinsam bewertet sowie die Analysemodelle weiter verfeinert. Niemand muss sich mit einer Programmiersprache auskennen. Besonders für Fachbereiche wird schnell erkennbar, welche Datenschwächen welche Auswirkungen auf die Aussagekraft der Kennzahlen oder auf die Ergebnisqualität von datengetriebenen Prozessen haben.
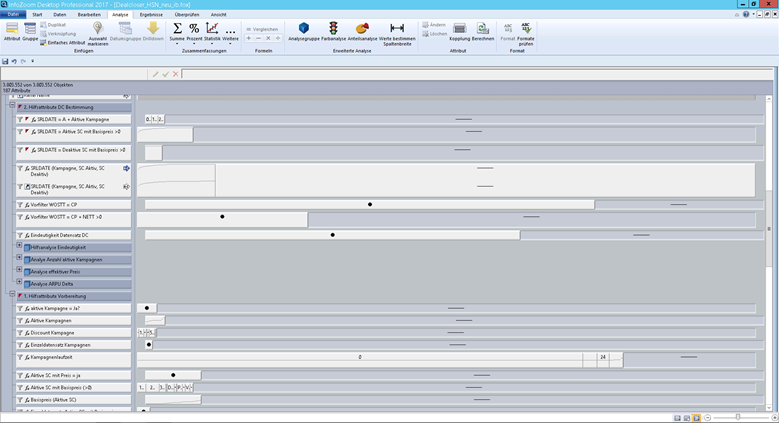
Schritt 4 – Reportmodell entwickeln
Im letzten Schritt wird das Report-Modell erstellt. Hier nutzen wir die Kombination InfoZoom/Excel. Selektionen in InfoZoom werden sofort in Excel wirksam. Auswirkungen auf die Kennzahlen im Report werden damit leicht nachvollziehbar.
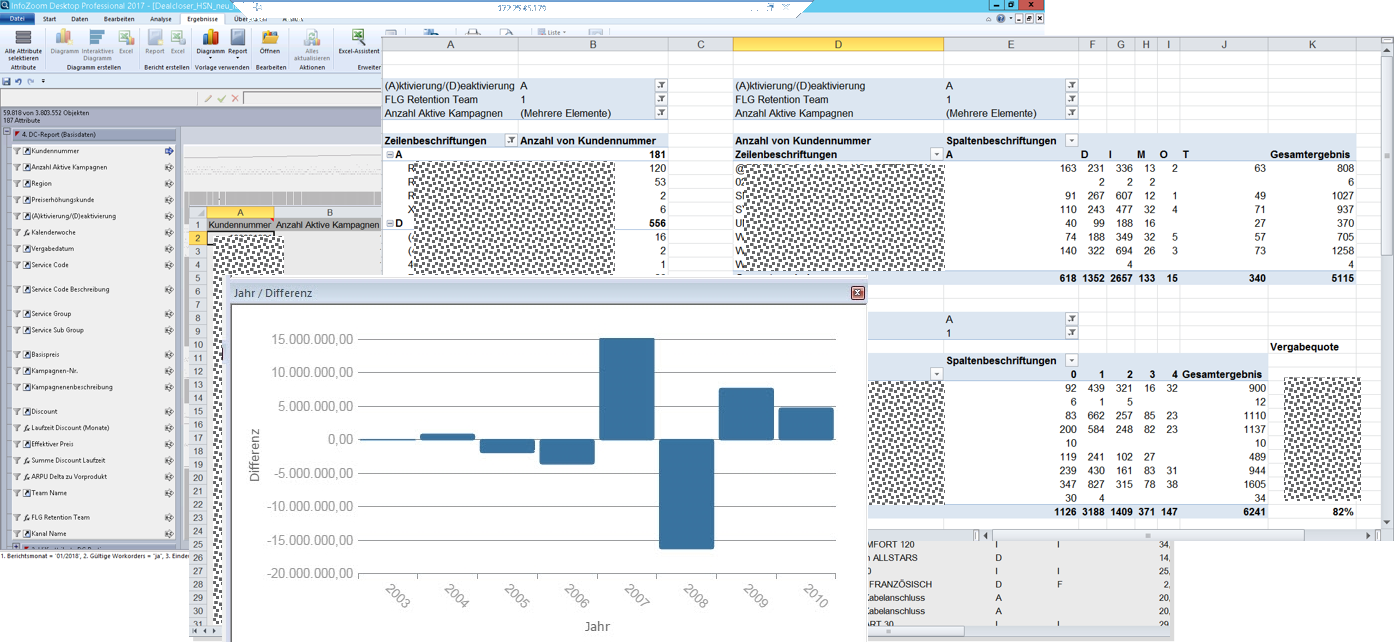
Metadaten für Wissenstransfer
Alle Schritte, die mit InfoZoom erstellt werden, sind in Form von Metadaten protokolliert. (Z.B. die verwendeten Daten und Tabellen, Tabellenverknüpfungen, Formate, Formeln, Klarnamen und original Attributnamen.) Somit wird nachvollziehbar, wie man auf die Ergebnisse gekommen ist und kann dieses Wissen weitergeben, z.B. an das Data Warehouse Team.
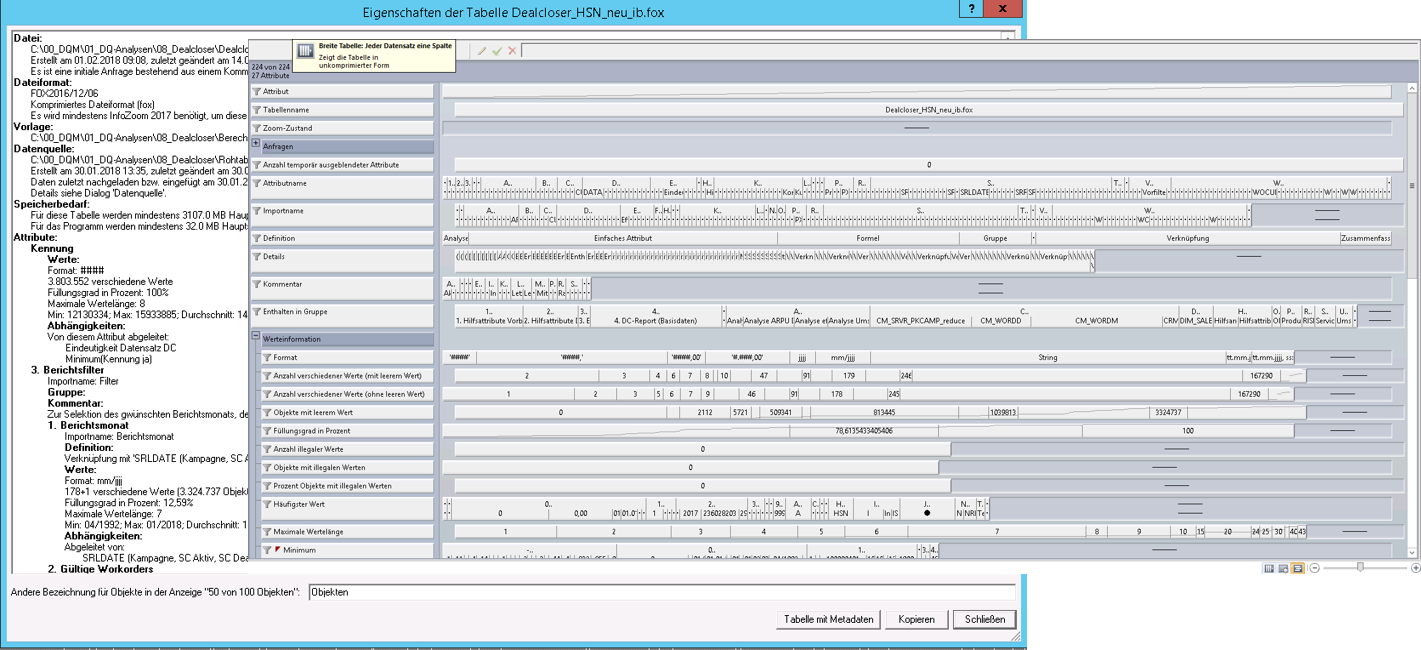
Fazit
Das Verfahren ermöglicht Organisationen schnell, flexibel, objektiv und für alle verständlich die Leistungsfähigkeit von Daten in Abhängigkeit ihres Erfüllungszwecks zu bewerten. Das frühzeitige Erkennen von Datenschwächen und deren Auswirkungen auf die faktenbasierte Entscheidungsfindung wie auf Prozessergebnisse ermöglicht es zeitnah entsprechende Maßnahmen abzuleiten und umzusetzen. Investitionen werden dadurch vor Misserfolgen geschützt. Projekte bleiben hinsichtlich Zeit und Budget steuerbar und die Erfolgschancen bleiben gewahrt oder werden sogar verbessert. Ich bin überzeugt, dass es für viele Organisationen attraktiv ist, das Verfahren zu adaptieren. Es ist einfach anpassbar und setzt im Besonderen in der Startphase auf bereits vorhandene Ressourcen und Werkzeuge. Das bedeutet geringe Einführungskosten, schnelle Lernkurve und Ergebnisse und damit einen frühen Return on Invest (ROI). Zusätzlich schafft es ein neues Bewusstsein für Daten und deren Einsatzmöglichkeiten und fördert eine iterative interdisziplinäre Zusammenarbeit. Silodenken in Organisationen können aufgelöst werden. Meine Sichtweise: Lieber 10 Prototypen á 10.000 €, als ein Projekt mit 1 Mio. € in den Sand gesetzt.
Anmerkung: Vorträge zu dem Thema "Data Governance und Leistungsbewertung von Daten" habe ich unteranderem auf dem Stammdatenforum 2018 in Düsseldorf gehalten sowie auf dem InfoZoom Best Practice Day auf Schloss Birlinghoven.
Lesen Sie auch:
- Aufzeichnung Webinar - Rapid Data Performance Assessment
- Data Governance, der Schlüssel zu einer erfolgreichen datenintelligenten Organisationskultur
- Data Strategy: Welche Erfolgsfaktoren sind relevant für nachhaltige Wettbewerbsvorteile durch KI-basierte Datenanalysen und Digitalisierung?
- Prozessorientierter Data Quality Index erfolgreich einführen
- Datenqualität messen: Mit 11 Kriterien Datenqualität quantifizieren
- Wie Sie schnell bewerten können, ob Sie ein Problem mit der Datenqualität haben
- Logikbäume: Mehr Transparenz zur Wirkung schlechter Datenqualität auf Unternehmensziele
Datenqualität, Business Intelligence, InfoZoom, Business Analytics, Datenqualitätsmanagement, Data Quality Management, Data Governance, Data Profiling, Model Driven Design, Datenmodellierung
- Geändert am .
- Aufrufe: 23186